论文阅读:The Quest for a Common Model of the Intelligent Decision Maker(智能体的通用模型)
date
Feb 13, 2024
slug
the-common-model-of-the-intelligent-agent
status
Published
tags
论文
AI
summary
Richard Sutton 最近发出来的一篇短论文。行文科普,野心狂大。想干的事情就是跨学科的建立决策机制的通用模型,然后开宗立派搞个新的决策科学。论文里对agent的阐述,让我找到了关于agent更好的中文翻译,之前对应『代理』听上去总是很奇怪,『决策者』应该更为贴切。
type
Post
cover
Richard Sutton 最近发出来的一篇短论文。行文科普,野心狂大。想干的事情就是跨学科的建立决策机制的通用模型,然后开宗立派搞个新的决策科学。论文里对agent的阐述,让我找到了关于agent更好的中文翻译,之前对应『代理』听上去总是很奇怪,『决策者』应该更为贴切。
论文地址:
阅读笔记:
1. The Quest
Multi-disciplinary Conference on Reinforcement Learning
Multi-disciplinary Conference on Reinforcement Learning and Decision Making (RLDM) is that there is value in all the disciplines interested in “learning and decision making over time to achieve a goal” coming together and sharing perspectives.
跨学科的强化学习同时共享『观点』从而达到目标。
2. Inter face Terminology
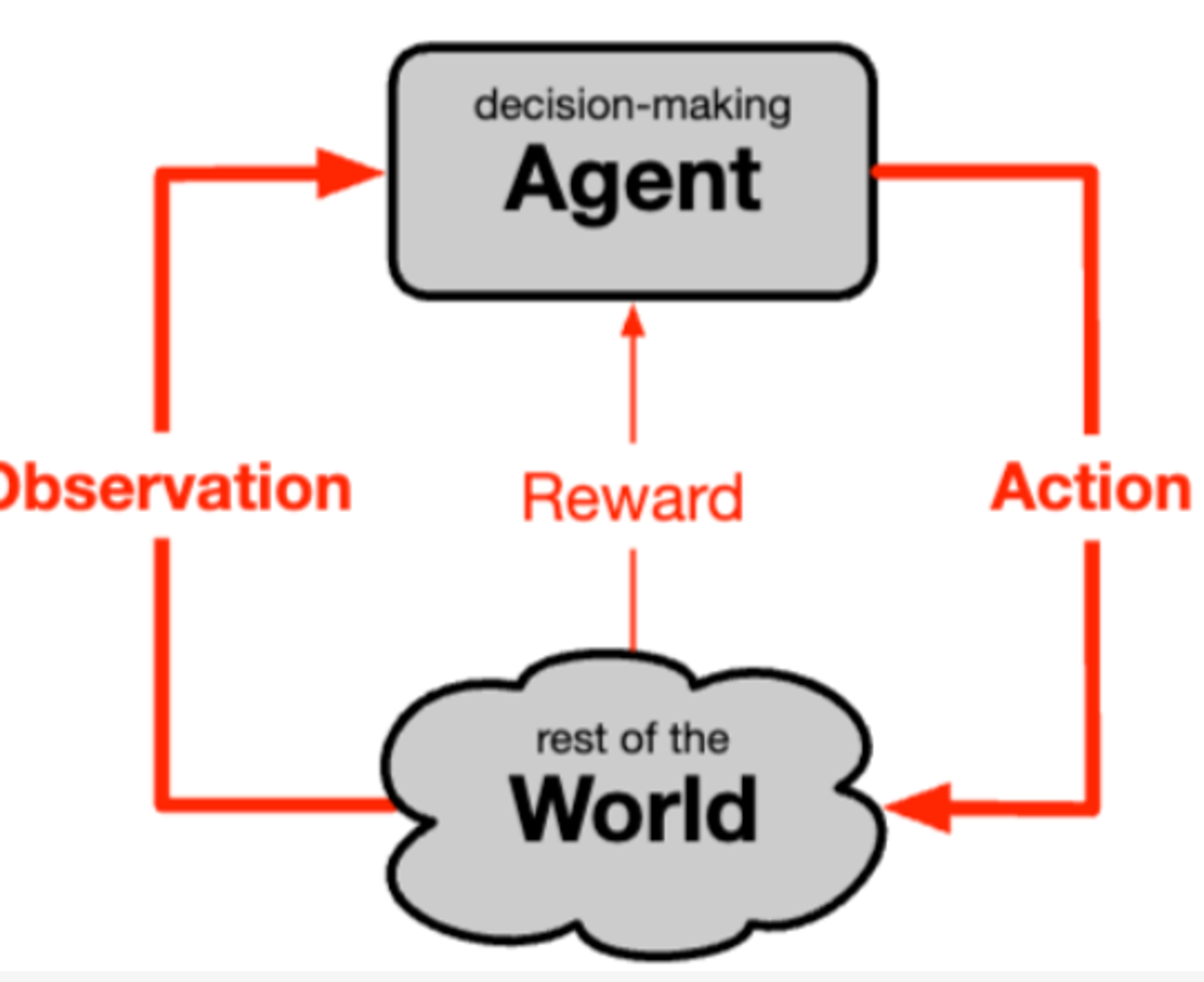
The term “agent” is also preferable to ”decision maker” because it connotes autonomy and purposiveness.
agent 可以理解 『决策者』,因为它常常意味着自治和目的性。agent 与外界(不包括自身)进行交互。
3. Ground Rules
尝试遵循的关于术语的基本规则和步骤:
1)确定单独于学科的概念,该词意欲传达的含义。
2)找到一个常识性词汇来捕捉该含义,而不偏向于某一学科。
3)重复前两个步骤,直到跨学科达成共识。
4. Additive Rewards
Additive Rewards:
Such additive rewards may be used to formulate the goal as a delay-discounted sum, as a sum over a finite horizon, or in terms of average reward per time step.
带折扣因子的回报累加和。别名(payoff , gain, utility),一般而言agent想要最大化。
Costs:
可以理解为『负收益』,一般 agent 想最小化 ,但实际上,。
5. Standard Components of the Decision-Making Agent
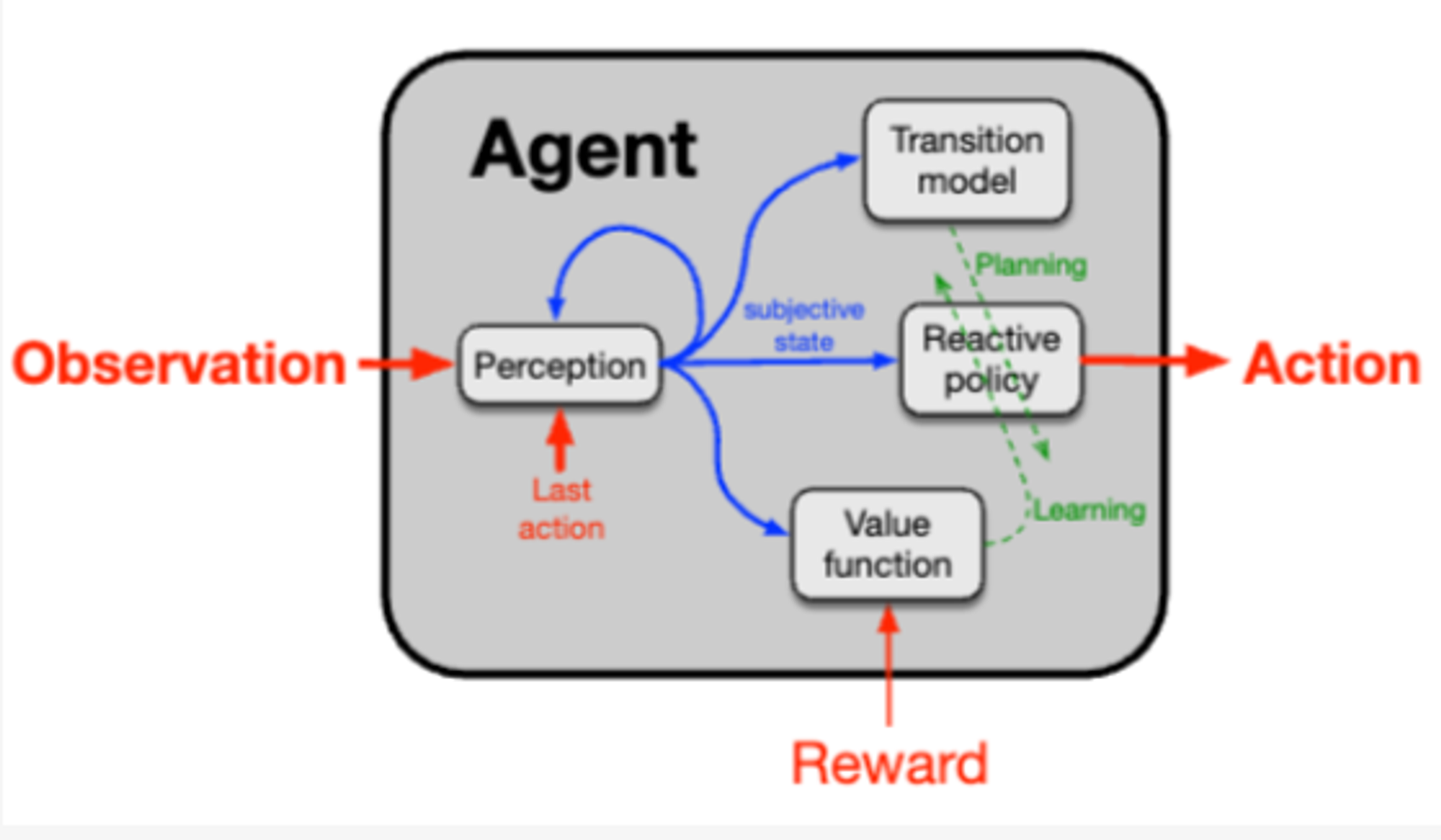
两张图有很大的相似性一些必要的组件:
- Perception: 感知组件处理观察和行动流以产生主观状态,这是迄今为止对代理-世界互动的总结,对于选择行动(反应性策略)以及预测未来奖励(值函数)和未来主观状态(转换模型)都非常有用。该状态是主观的,因为它是相对于代理的观察和行动而言的,并且可能不对应于世界的实际内部工作方式。
- reactive policy:将整体行动生成分解为这两个部分——感知和策略——在许多学科中都很常见。在工程学中,常常假设感知是给定的,不是学习的,甚至不是代理的一部分。工程学清楚地提出了一个反应性策略的概念,通常是通过计算或分析推导得到的。人工智能系统更常假设在行动之前可以进行大量处理(例如,下棋程序)。古典心理学有其刺激-响应关联。在心理学中,通常将感知视为支持但在行动之前发生的一些事情,并且可以独立于其对特定行动的影响进行研究。
- value function:共同模型的价值函数组件将主观状态(或状态-动作对)映射到其可取性的标量评估,操作上定义为随之而来的预期累积奖励。这个评估是快速的,独立于其理由(类似直觉),但可能基于长期经验(甚至是专家设计或几代进化)或来自有效存储或缓存的广泛计算。无论哪种方式,这些评估都可以迅速调用,以支持改变反应性策略的过程。
- transition model:转换模型接收状态并预测采取各种行动会导致的下一个状态。转换模型可以称为“世界模型”,但这会夸大其作用,因为构成世界模型的很多内容实际上在感知组件及其状态表示中。转换模型用于模拟各种行动的效果,并借助价值函数评估可能的结果,改变反应性策略以支持预测良好结果的行动,不支持预测不良结果的行动。当这个过程在实际执行行动之前进行时,甚至可能在没有访问状态的情况下进行时,将其称为“规划”或甚至“推理”是适当的(世界地图)。